TRIE
Tugas Pre UAS Struktur Data
Nama : Bagus Riady
Nim : 1401140384
Kelas : 02 PVT
Pengertian Trie
Dalam ilmu komputer, trie, atau pohon awalan, adalah sebuah pohon struktur data yang memerintahkan digunakan untuk menyimpan sebuah array asosiatif di mana kunci biasanya string. Tidak seperti pohon pencarian biner, tidak ada node di pohon menyimpan kunci yang terkait dengan simpul itu; sebaliknya, posisinya di pohon menunjukkan apa kunci itu terkait dengan. Semua keturunan dari sebuah node memiliki awalan umum dari string yang berhubungan dengan node itu, dan akar dikaitkan dengan string kosong. Nilai biasanya tidak berhubungan dengan setiap node, hanya dengan beberapa node daun dan batin yang sesuai dengan kunci yang menarik.
Para trie Istilah berasal dari pengambilan. Setelah etimologi, penemu, Edward Fredkin, mengucapkannya / tri ː / "pohon" Namun, itu diucapkan / traɪ / "mencoba" oleh penulis lain.
Dalam contoh yang ditunjukkan, kunci tercantum dalam node dan nilai-nilai di bawah mereka. Setiap kata bahasa Inggris yang lengkap memiliki nilai integer sewenang-wenang yang terkait dengan itu. Trie dapat dilihat sebagai automaton deterministik yang terbatas, meskipun simbol pada setiap sisinya ini seringkali implisit dalam urutan cabang.
Hal ini tidak perlu untuk kunci secara eksplisit disimpan dalam node. (Dalam gambar, kata-kata hanya ditampilkan untuk menggambarkan bagaimana trie bekerja.)
Meskipun paling umum, mencoba tidak perlu mengetik dengan string karakter. Algoritma yang sama dengan mudah dapat diadaptasi untuk melayani fungsi yang sama daftar memerintahkan setiap membangun, misalnya, permutasi pada daftar angka atau bentuk. Secara khusus, trie bitwise adalah kunci pada bit individu membuat sebuah ukuran, pendek tetap bit seperti nomor integer atau pointer ke memori.
Para trie Istilah berasal dari pengambilan. Setelah etimologi, penemu, Edward Fredkin, mengucapkannya / tri ː / "pohon" Namun, itu diucapkan / traɪ / "mencoba" oleh penulis lain.
Dalam contoh yang ditunjukkan, kunci tercantum dalam node dan nilai-nilai di bawah mereka. Setiap kata bahasa Inggris yang lengkap memiliki nilai integer sewenang-wenang yang terkait dengan itu. Trie dapat dilihat sebagai automaton deterministik yang terbatas, meskipun simbol pada setiap sisinya ini seringkali implisit dalam urutan cabang.
Hal ini tidak perlu untuk kunci secara eksplisit disimpan dalam node. (Dalam gambar, kata-kata hanya ditampilkan untuk menggambarkan bagaimana trie bekerja.)
Meskipun paling umum, mencoba tidak perlu mengetik dengan string karakter. Algoritma yang sama dengan mudah dapat diadaptasi untuk melayani fungsi yang sama daftar memerintahkan setiap membangun, misalnya, permutasi pada daftar angka atau bentuk. Secara khusus, trie bitwise adalah kunci pada bit individu membuat sebuah ukuran, pendek tetap bit seperti nomor integer atau pointer ke memori.
Contoh struktur Trie :

Keuntungan yang relatif dalam mencari menggunakan cara lain
-
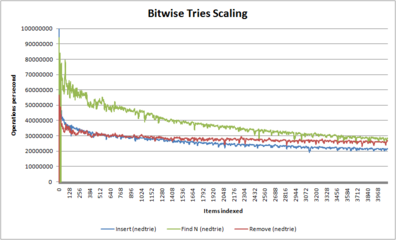 Bagaimana mencoba Fredkin skala
Bagaimana mencoba Fredkin skala
(dalam hal ini, nedtries yang merupakan implementasi di tempat dan karena itu memiliki kurva lebih curam daripada memori dinamis berbasis implementasi trie) -
 Bagaimana pohon merah hitam skala
Bagaimana pohon merah hitam skala
(dalam hal ini, rbtree.h BSD, dan jelas menunjukkan O klasik (log N) perilaku) -
 Bagaimana tabel hash skala
Bagaimana tabel hash skala
(dalam hal ini, uthash, dan ketika rata-rata menunjukkan O klasik (1) perilaku)
Tidak seperti algoritma lainnya, mencoba memiliki fitur aneh yang waktu untuk memasukkan, atau untuk menghapus atau untuk menemukan hampir identik karena jalur kode diikuti untuk setiap hampir identik. Akibatnya, untuk situasi di mana kode menyisipkan, menghapus dan menemukan dalam mencoba ukuran yang sama dgn mudah bisa mengalahkan pohon pencarian biner atau tabel hash bahkan, serta menjadi lebih baik untuk instruksi CPU dan cache cabang.
Berikut ini adalah keuntungan utama dari mencoba lebih dari pohon pencarian biner (BSTs):
Mencari kunci lebih cepat. Mencari sebuah kunci dengan panjang m mengambil kasus terburuk O (m) waktu. Sebuah BST melakukan O (log (n)) perbandingan kunci, dimana n adalah jumlah elemen dalam pohon, karena pencarian tergantung pada kedalaman pohon, yang logaritmik dalam jumlah tombol jika pohon seimbang. Oleh karena itu dalam kasus terburuk, BST membutuhkan O (m log n) waktu. Selain itu, dalam kasus terburuk log (n) akan mendekati m. Juga, operasi sederhana mencoba digunakan selama pencarian, seperti pengindeksan array menggunakan karakter, yang cepat pada mesin nyata.
Mencoba adalah ruang lebih efisien ketika mereka mengandung sejumlah besar kunci pendek, karena node dibagi antara kunci dengan subsequence awal umum.
Mencoba memfasilitasi terpanjang-prefix pencocokan, membantu menemukan kunci berbagi awalan terpanjang mungkin karakter semua unik.
Jumlah node internal dari akar ke daun sama dengan panjang kunci. Menyeimbangkan pohon karena itu ada kekhawatiran.
Berikut ini adalah keuntungan utama dari mencoba lebih dari tabel hash:
Mencoba iterasi dukungan memerintahkan, sedangkan iterasi lebih dari tabel hash akan menghasilkan urutan acak semu yang diberikan oleh fungsi hash (juga, urutan tabrakan hash adalah implementasi didefinisikan), yang biasanya berarti.
Mencoba memfasilitasi pencocokan awalan terpanjang-, tapi hashing tidak, sebagai konsekuensi di atas. Pertunjukan seperti "cocok terdekat" menemukan dapat, tergantung pada implementasi, akan secepat sebagai tepat menemukan.
Mencoba cenderung lebih cepat rata-rata pada saat pemasangan dari tabel hash tabel hash harus karena membangun kembali indeks mereka ketika menjadi penuh - operasi yang sangat mahal. Mencoba karena itu memiliki jauh lebih baik dibatasi biaya waktu kasus terburuk, yang penting untuk program latency sensitif.
Dengan menghindari fungsi hash, mencoba umumnya lebih cepat daripada tabel hash untuk kunci kecil seperti integer dan pointer.
Aplikasi
Sebagai penggantian struktur data lain
Seperti disebutkan, trie memiliki sejumlah keunggulan dibandingkan pohon pencarian biner [4] trie A juga dapat digunakan untuk mengganti tabel hash, dimana memiliki keuntungan sebagai berikut.:
Mencari data dalam trie adalah lebih cepat dalam kasus terburuk, O (m) waktu, dibandingkan dengan tabel hash yang tidak sempurna. Sebuah tabel hash yang tidak sempurna dapat memiliki kunci tabrakan. Sebuah tabrakan utama adalah pemetaan fungsi hash dari kunci yang berbeda untuk posisi yang sama dalam tabel hash. Kasus-terburuk kecepatan lookup dalam tabel hash yang tidak sempurna adalah O (N) waktu, tapi jauh lebih biasanya adalah O (1), dengan O (m) waktu yang dihabiskan mengevaluasi hash.
Tidak ada tabrakan kunci yang berbeda dalam sebuah trie.
Ember di sebuah trie yang analog dengan tabel hash ember yang menyimpan kunci tabrakan hanya diperlukan jika satu kunci dikaitkan dengan lebih dari satu nilai.
Tidak perlu untuk menyediakan fungsi hash atau untuk mengubah fungsi hash sebagai kunci yang lebih yang ditambahkan ke sebuah trie.
Trie dapat memberikan urutan abjad dari entri dengan kunci.
Mencoba memiliki beberapa kekurangan juga:
Mencoba dapat lebih lambat dalam beberapa kasus dari tabel hash untuk mencari data, terutama jika data langsung diakses pada hard disk drive atau beberapa perangkat penyimpanan sekunder lainnya mana waktu akses acak tinggi dibandingkan dengan memori utama [5].
Beberapa tombol, seperti nomor floating point, dapat menyebabkan rantai panjang dan prefiks yang tidak terlalu bermakna. Namun demikian sebuah trie bitwise dapat menangani format standar IEEE tunggal dan ganda nomor titik mengambang.



Menyortir leksikografis dari satu set kunci dapat dicapai dengan algoritma sederhana berbasis trie sebagai berikut:
Masukkan semua kunci dalam sebuah trie.
Output semua kunci dalam trie dengan cara pre-order traversal, yang menghasilkan output yang dalam rangka leksikografis meningkat. Pre-order traversal adalah semacam depth-first traversal. Di-order traversal jenis lain dari depth-first traversal yang lebih sesuai untuk keluaran nilai-nilai yang berada dalam pohon pencarian biner bukan sebuah trie.
Algoritma ini adalah bentuk semacam radix.
Trie Sebuah bentuk struktur data dasar Burstsort;. Saat ini (2007) tercepat diketahui, memori / cache berbasis, string algoritma sorting
Sebuah algoritma paralel untuk menyortir kunci N didasarkan pada mencoba adalah O (1) jika ada prosesor N dan panjang kunci memiliki bagian atas yang konstan terikat. Ada potensi bahwa kunci mungkin bertabrakan dengan memiliki prefiks umum atau dengan menjadi identik dengan satu sama lain, mengurangi atau menghilangkan keuntungan kecepatan memiliki beberapa prosesor yang beroperasi di paralel....
Mencoba Mengompresi
Ketika trie ini kebanyakan statis, yaitu semua insersi atau delesi kunci dari trie prefilled cacat dan pencarian hanya diperlukan, dan ketika node trie tidak mengetik dengan data tertentu node (atau jika data node umum) adalah mungkin untuk kompres representasi trie dengan menggabungkan cabang umum . Aplikasi ini biasanya digunakan untuk mengompresi tabel lookup ketika set kunci total sangat jarang disimpan dalam ruang representasi mereka.
Sebagai contoh mungkin digunakan untuk mewakili bitsets jarang (yaitu himpunan bagian dari satu set jauh lebih besar tetap enumerable) menggunakan trie mengetik dengan posisi sedikit elemen dalam set penuh, dengan kunci yang dibuat dari string bit yang diperlukan untuk menyandikan posisi terpisahkan setiap elemen. Trie kemudian akan memiliki sangat merosot formulir dengan banyak cabang yang hilang, dan kompresi menjadi mungkin dengan menyimpan node daun (mengatur segmen dengan panjang tetap) dan menggabungkan mereka setelah mendeteksi pengulangan pola umum atau dengan mengisi kesenjangan yang tidak terpakai.
Kompresi tersebut juga biasanya digunakan, dalam pelaksanaan berbagai tabel lookup cepat diperlukan untuk mengambil sifat karakter Unicode (misalnya untuk merepresentasikan tabel kasus pemetaan, atau tabel lookup yang berisi kombinasi karakter menggabungkan dasar dan diperlukan untuk mendukung Unicode normalisasi). Untuk aplikasi tersebut, representasi mirip dengan mengubah sebuah meja yang sangat besar jarang unidimensional ke matriks multidimensi, dan kemudian menggunakan koordinat di hiper-matriks sebagai kunci string dari trie terkompresi. Kompresi maka akan terdiri dari mendeteksi dan penggabungan kolom umum dalam hiper-matriks untuk memampatkan dimensi terakhir dalam kunci; setiap dimensi dari toko hypermatrix posisi awal dalam vektor penyimpanan dimensi berikutnya untuk setiap nilai koordinat, dan vektor yang dihasilkan sendiri kompresibel saat itu juga jarang, sehingga setiap dimensi (terkait ke tingkat lapisan dalam trie) dikompresi secara terpisah.
Beberapa implementasi tidak mendukung kompresi seperti data dalam mencoba jarang dinamis dan memungkinkan penyisipan dan penghapusan dalam kompresi mencoba, tetapi umumnya ini memiliki biaya yang signifikan ketika segmen dikompresi harus split atau digabung, dan beberapa tradeoff harus dibuat antara ukuran terkecil dari trie dikompresi dan kecepatan update, dengan membatasi kisaran pencarian global untuk membandingkan cabang umum dalam trie jarang.
Hasil kompresi seperti mungkin terlihat mirip dengan berusaha untuk mengubah trie ke dalam grafik asiklik diarahkan (DAG), karena sebaliknya berubah dari DAG untuk trie adalah jelas dan selalu mungkin, namun dibatasi oleh bentuk dari kunci yang dipilih untuk indeks node.
Pendekatan lain kompresi adalah untuk "mengungkap" struktur data ke dalam array byte tunggal . Pendekatan ini menghilangkan kebutuhan untuk pointer node yang mengurangi kebutuhan memori secara substansial dan membuat pemetaan memori mungkin yang memungkinkan manajer memori virtual untuk memuat data ke memori yang sangat efisien.
Pendekatan lain kompresi adalah "paket" trie . Liang menjelaskan implementasi ruang-efisien dari trie dikemas jarang diterapkan untuk hyphenation, di mana keturunan setiap node dapat disisipkan dalam memori.
Ketika trie ini kebanyakan statis, yaitu semua insersi atau delesi kunci dari trie prefilled cacat dan pencarian hanya diperlukan, dan ketika node trie tidak mengetik dengan data tertentu node (atau jika data node umum) adalah mungkin untuk kompres representasi trie dengan menggabungkan cabang umum . Aplikasi ini biasanya digunakan untuk mengompresi tabel lookup ketika set kunci total sangat jarang disimpan dalam ruang representasi mereka.
Sebagai contoh mungkin digunakan untuk mewakili bitsets jarang (yaitu himpunan bagian dari satu set jauh lebih besar tetap enumerable) menggunakan trie mengetik dengan posisi sedikit elemen dalam set penuh, dengan kunci yang dibuat dari string bit yang diperlukan untuk menyandikan posisi terpisahkan setiap elemen. Trie kemudian akan memiliki sangat merosot formulir dengan banyak cabang yang hilang, dan kompresi menjadi mungkin dengan menyimpan node daun (mengatur segmen dengan panjang tetap) dan menggabungkan mereka setelah mendeteksi pengulangan pola umum atau dengan mengisi kesenjangan yang tidak terpakai.
Kompresi tersebut juga biasanya digunakan, dalam pelaksanaan berbagai tabel lookup cepat diperlukan untuk mengambil sifat karakter Unicode (misalnya untuk merepresentasikan tabel kasus pemetaan, atau tabel lookup yang berisi kombinasi karakter menggabungkan dasar dan diperlukan untuk mendukung Unicode normalisasi). Untuk aplikasi tersebut, representasi mirip dengan mengubah sebuah meja yang sangat besar jarang unidimensional ke matriks multidimensi, dan kemudian menggunakan koordinat di hiper-matriks sebagai kunci string dari trie terkompresi. Kompresi maka akan terdiri dari mendeteksi dan penggabungan kolom umum dalam hiper-matriks untuk memampatkan dimensi terakhir dalam kunci; setiap dimensi dari toko hypermatrix posisi awal dalam vektor penyimpanan dimensi berikutnya untuk setiap nilai koordinat, dan vektor yang dihasilkan sendiri kompresibel saat itu juga jarang, sehingga setiap dimensi (terkait ke tingkat lapisan dalam trie) dikompresi secara terpisah.
Beberapa implementasi tidak mendukung kompresi seperti data dalam mencoba jarang dinamis dan memungkinkan penyisipan dan penghapusan dalam kompresi mencoba, tetapi umumnya ini memiliki biaya yang signifikan ketika segmen dikompresi harus split atau digabung, dan beberapa tradeoff harus dibuat antara ukuran terkecil dari trie dikompresi dan kecepatan update, dengan membatasi kisaran pencarian global untuk membandingkan cabang umum dalam trie jarang.
Hasil kompresi seperti mungkin terlihat mirip dengan berusaha untuk mengubah trie ke dalam grafik asiklik diarahkan (DAG), karena sebaliknya berubah dari DAG untuk trie adalah jelas dan selalu mungkin, namun dibatasi oleh bentuk dari kunci yang dipilih untuk indeks node.
Pendekatan lain kompresi adalah untuk "mengungkap" struktur data ke dalam array byte tunggal . Pendekatan ini menghilangkan kebutuhan untuk pointer node yang mengurangi kebutuhan memori secara substansial dan membuat pemetaan memori mungkin yang memungkinkan manajer memori virtual untuk memuat data ke memori yang sangat efisien.
Pendekatan lain kompresi adalah "paket" trie . Liang menjelaskan implementasi ruang-efisien dari trie dikemas jarang diterapkan untuk hyphenation, di mana keturunan setiap node dapat disisipkan dalam memori.
Contoh Trie
1. ALGO
2. API
3. BOM
4. BOS
5. BOSAN
6. BOR

Insertion in Trie
Untuk memasukkan kata ke trie, kita dapat menggunakan kode ini:
void insert(struct trie *curr, char *p) {
if ( curr->edge[*p] == 0 )
curr->edge[*p] = newnode(*p);
if ( *p == 0 ) curr->word = 1;
else insert(curr->edge[*p],p+1);
}
else insert(curr->edge[*p],p+1);
}
Dan jika kita ingin memasukkan data, tetapi belum ada data(kosong), kita haruslah memesan memori terlebih dahulu, kita bisa menggunakan kode ini :
struct trie* newnode(char x) {
struct trie* node =
(struct trie*)malloc(sizeof(struct trie));
node->chr = x;
node->word = 0;
for (i = 0; i < 128; i++ )
node->edge[i] = 0;
return node;
Referensi :
http://en.wikipedia.org/wiki/Trie
http://www.informatika.org/
Tidak ada komentar:
Posting Komentar